Output
An OutputSeq object is the result of running a language model on some input data. It contains not only the output sequence of words generated by the model, but also other data collecting during the generation process that is useful to analyze the model.
In addition to the data, the object has methods to create plots and visualizations of that collected data. These include:
- layer_predictions()
Which tokens did the model consider as the best outputs for a specific position in the sequence? - rankings()
After the model chooses an output token for a specific position, this visual looks back at the ranking of this token at each layer of the model when it was generated (layers assign scores to candidate output tokens, the higher the "probability" score, the higher the ranking of the token). - rankings_watch()
Shows the rankings of multiple tokens as the model scored them for a single position. For example, if the input is "The cat ___", we use this method to observe how the model ranked the words "is", "are", "was" as candidates to fill in the blank. - saliency()
How important was each input token in the selection of calculating the output token?
To process neuron activations, OutputSeq has methods to reduce the dimensionality and reveal underlying patterns in neuron firings. These are:
__init__(self, token_ids=None, n_input_tokens=None, tokenizer=None, output_text=None, tokens=None, encoder_hidden_states=None, decoder_hidden_states=None, embedding_states=None, attribution=None, activations=None, collect_activations_layer_nums=None, attention=None, model_outputs=None, model_type='mlm', lm_head=None, device='cpu')
special
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
token_ids |
|
The input token ids. Dimensions: (batch, position) |
None |
n_input_tokens |
|
Int. The number of input tokens in the sequence. |
None |
tokenizer |
|
huggingface tokenizer associated with the model generating this output |
None |
output_text |
|
The output text generated by the model (if processed with generate()) |
None |
tokens |
|
A list of token text. Shorthand to passing the token ids by the tokenizer. dimensions are (batch, position) |
None |
hidden_states |
|
A tensor of dimensions (layer, position, hidden_dimension). In layer, index 0 is for embedding hidden_state. |
required |
attribution |
|
A list of attributions. One element per generated token. Each element is a list giving a value for tokens from 0 to right before the generated token. |
None |
activations |
|
The activations collected from model processing. Shape is (batch, layer, neurons, position) |
None |
collect_activations_layer_nums |
|
None |
|
attention |
|
The attention tensor retrieved from the language model |
None |
model_outputs |
|
Raw return object returned by the model |
None |
lm_head |
|
The trained language model head from a language model projecting a hidden state to an output vocabulary associated with teh tokenizer. |
None |
device |
|
"cuda" or "cpu" |
'cpu' |
Source code in ecco/output.py
def __init__(self,
token_ids=None,
n_input_tokens=None,
tokenizer=None,
output_text=None,
tokens=None,
encoder_hidden_states=None,
decoder_hidden_states=None,
embedding_states=None,
attribution=None,
activations=None,
collect_activations_layer_nums=None,
attention=None,
model_outputs=None,
model_type: str= 'mlm',
lm_head=None,
device='cpu'):
"""
Args:
token_ids: The input token ids. Dimensions: (batch, position)
n_input_tokens: Int. The number of input tokens in the sequence.
tokenizer: huggingface tokenizer associated with the model generating this output
output_text: The output text generated by the model (if processed with generate())
tokens: A list of token text. Shorthand to passing the token ids by the tokenizer.
dimensions are (batch, position)
hidden_states: A tensor of dimensions (layer, position, hidden_dimension).
In layer, index 0 is for embedding hidden_state.
attribution: A list of attributions. One element per generated token.
Each element is a list giving a value for tokens from 0 to right before the generated token.
activations: The activations collected from model processing.
Shape is (batch, layer, neurons, position)
collect_activations_layer_nums:
attention: The attention tensor retrieved from the language model
model_outputs: Raw return object returned by the model
lm_head: The trained language model head from a language model projecting a
hidden state to an output vocabulary associated with teh tokenizer.
device: "cuda" or "cpu"
"""
self.token_ids = token_ids
self.tokenizer = tokenizer
self.n_input_tokens = n_input_tokens
self.output_text = output_text
self.tokens = tokens
self.encoder_hidden_states = encoder_hidden_states
self.decoder_hidden_states = decoder_hidden_states
self.embedding_states = embedding_states
self.attribution = attribution
self.activations = activations
self.collect_activations_layer_nums = collect_activations_layer_nums
self.model_outputs = model_outputs
self.attention_values = attention
self.lm_head = lm_head
self.device = device
self.model_type = model_type
self._path = os.path.dirname(ecco.__file__)
layer_predictions(self, position=1, topk=10, layer=None, **kwargs)
Visualization plotting the topk predicted tokens after each layer (using its hidden state).
Examples:

Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
position |
int |
The index of the output token to trace |
1 |
topk |
Optional[int] |
Number of tokens to show for each layer |
10 |
layer |
Optional[int] |
None shows all layers. Can also pass an int with the layer id to show only that layer |
None |
Source code in ecco/output.py
def layer_predictions(self, position: int = 1, topk: Optional[int] = 10, layer: Optional[int] = None, **kwargs):
"""
Visualization plotting the topk predicted tokens after each layer (using its hidden state).
Example:

Args:
position: The index of the output token to trace
topk: Number of tokens to show for each layer
layer: None shows all layers. Can also pass an int with the layer id to show only that layer
"""
assert self.model_type != 'mlm', "method not supported for Masked-LMs"
_, dec_hidden_states = self._get_hidden_states()
assert dec_hidden_states is not None, "decoder hidden states not found"
if position == 0:
raise ValueError(f"'position' is set to 0. There is never a hidden state associated with this position."
f"Possible values are 1 and above -- the position of the token of interest in the sequence")
if self.model_type == 'enc-dec':
# For enc-dec LMs, the position starts at the first generated token, not as in causal LMs
# In enc-dec LMs, the position is relative. By that means, position self.n_input_tokens is the first generated token
new_position = position - self.n_input_tokens
assert new_position >= 0, f"position={position} not supported, minimum is " \
f"position={self.n_input_tokens} for the first generated token"
position = new_position
if layer is not None:
# If a layer is specified, choose it only.
assert dec_hidden_states is not None
dec_hidden_states = dec_hidden_states[layer].unsqueeze(0)
k = topk
top_tokens = []
probs = []
data = []
# loop through layer levels
for layer_no, h in enumerate(dec_hidden_states):
hidden_state = h[position - 1]
# Use lm_head to project the layer's hidden state to output vocabulary
logits = self.lm_head(self.to(hidden_state))
softmax = F.softmax(logits, dim=-1)
# softmax dims are (number of words in vocab) - 50257 in GPT2
sorted_softmax = self.to(torch.argsort(softmax))
# Not currently used. If we're "watching" a specific token, this gets its ranking
# idx = sorted_softmax.shape[0] - torch.nonzero((sorted_softmax == watch)).flatten()
layer_top_tokens = [self.tokenizer.decode(t) for t in sorted_softmax[-k:]][::-1]
top_tokens.append(layer_top_tokens)
layer_probs = softmax[sorted_softmax[-k:]].cpu().detach().numpy()[::-1]
probs.append(layer_probs.tolist())
# Package in output format
layer_data = []
for idx, (token, prob) in enumerate(zip(layer_top_tokens, layer_probs)):
layer_num = layer if layer is not None else layer_no
layer_data.append({'token': token,
'prob': str(prob),
'ranking': idx + 1,
'layer': layer_num
})
data.append(layer_data)
d.display(d.HTML(filename=os.path.join(self._path, "html", "setup.html")))
d.display(d.HTML(filename=os.path.join(self._path, "html", "basic.html")))
js = f"""
requirejs(['basic', 'ecco'], function(basic, ecco){{
const viz_id = basic.init()
let pred = new ecco.LayerPredictions({{
parentDiv: viz_id,
data:{json.dumps(data)}
}})
pred.init()
}}, function (err) {{
console.log(viz_id, err);
}})"""
d.display(d.Javascript(js))
if 'printJson' in kwargs and kwargs['printJson']:
print(data)
return data
rankings(self, **kwargs)
Plots the rankings (across layers) of the tokens the model selected. Each column is a position in the sequence. Each row is a layer.
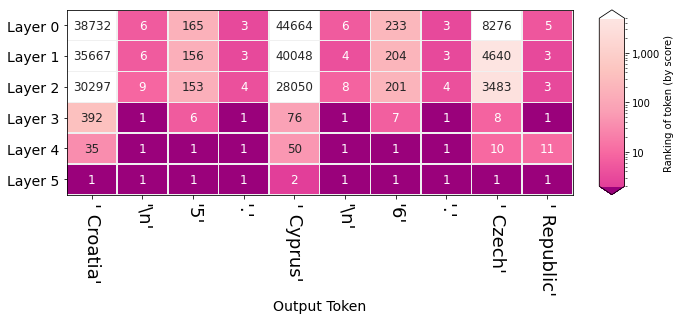
Source code in ecco/output.py
def rankings(self, **kwargs):
"""
Plots the rankings (across layers) of the tokens the model selected.
Each column is a position in the sequence. Each row is a layer.

"""
assert self.model_type != 'mlm', "method not supported for Masked-LMs"
_, dec_hidden_states = self._get_hidden_states()
assert dec_hidden_states is not None, "decoder hidden states not found"
n_layers_dec = len(dec_hidden_states)
if self.model_type == 'causal':
position = dec_hidden_states.shape[1] - self.n_input_tokens + 1
elif self.model_type == 'enc-dec':
position = dec_hidden_states.shape[1]
else:
raise NotImplemented(f"model_type={self.model_type} not supported")
rankings = np.zeros((n_layers_dec, position), dtype=np.int32)
predicted_tokens = np.empty((n_layers_dec, position), dtype='U25')
token_found_mask = np.ones((n_layers_dec, position))
# loop through layer levels
for i, level in enumerate(dec_hidden_states):
# Loop through generated/output positions
offset = 0 if self.model_type == 'enc-dec' else self.n_input_tokens - 1
for j, hidden_state in enumerate(level[offset:]):
# Project hidden state to vocabulary
# (after debugging pain: ensure input is on GPU, if appropriate)
logits = self.lm_head(self.to(hidden_state))
# Sort by score (ascending)
sorted = torch.argsort(logits)
# What token was sampled in this position?
offset = self.n_input_tokens + 1 if self.model_type == 'enc-dec' else self.n_input_tokens
token_id = torch.tensor(self.token_ids[0][offset + j])
# token_id = self.token_ids.clone().detach()[self.n_input_tokens + j]
# What's the index of the sampled token in the sorted list?
r = torch.nonzero((sorted == token_id)).flatten()
# subtract to get ranking (where 1 is the top scoring, because sorting was in ascending order)
ranking = sorted.shape[0] - r
token = self.tokenizer.decode([token_id])
predicted_tokens[i, j] = token
rankings[i, j] = int(ranking)
if token_id == self.token_ids[0][j + 1]:
token_found_mask[i, j] = 0
input_tokens = [repr(t) for t in self.tokens[0][self.n_input_tokens - 1:-1]]
offset = self.n_input_tokens + 1 if self.model_type == 'enc-dec' else self.n_input_tokens
output_tokens = [repr(t) for t in self.tokens[0][offset:]]
lm_plots.plot_inner_token_rankings(input_tokens,
output_tokens,
rankings,
**kwargs)
if 'printJson' in kwargs and kwargs['printJson']:
data = {
'input_tokens': input_tokens,
'output_tokens': output_tokens,
'rankings': rankings,
'predicted_tokens': predicted_tokens,
'token_found_mask': token_found_mask
}
print(data)
return data
rankings_watch(self, watch=None, position=-1, **kwargs)
Plots the rankings of the tokens whose ids are supplied in the watch list. Only considers one position.
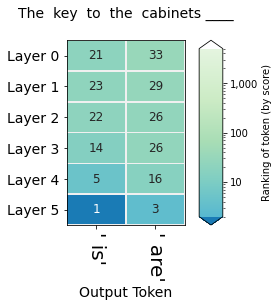
Source code in ecco/output.py
def rankings_watch(self, watch: List[int] = None, position: int = -1, **kwargs):
"""
Plots the rankings of the tokens whose ids are supplied in the watch list.
Only considers one position.

"""
assert self.model_type != 'mlm', "method not supported for Masked-LMs"
_, dec_hidden_states = self._get_hidden_states()
assert dec_hidden_states is not None, "decoder hidden states not found"
if position != -1:
if self.model_type == 'causal':
position = position - 1 # e.g. position 5 corresponds to hidden state 4
elif self.model_type == 'enc-dec':
# In enc-dec LMs, the position is relative. By that means, position self.n_input_tokens + 1 is the first generated token
new_position = position - 1 - self.n_input_tokens
assert new_position >= 0, f"position={position} not supported, minimum is " \
f"position={self.n_input_tokens + 1} for the first generated token"
position = new_position
else:
raise NotImplemented(f"model_type={self.model_type} not supported")
n_layers_dec = len(dec_hidden_states) if dec_hidden_states is not None else 0
n_tokens_to_watch = len(watch)
rankings = np.zeros((n_layers_dec, n_tokens_to_watch), dtype=np.int32)
# loop through layer levels
for i, level in enumerate(dec_hidden_states):
# Loop through generated/output positions
for j, token_id in enumerate(watch):
hidden_state = level[position]
# Project hidden state to vocabulary
# (after debugging pain: ensure input is on GPU, if appropriate)
logits = self.lm_head(self.to(hidden_state))
# Sort by score (ascending)
sorted = torch.argsort(logits)
# What token was sampled in this position?
token_id = torch.tensor(token_id)
# What's the index of the sampled token in the sorted list?
r = torch.nonzero((sorted == token_id)).flatten()
# subtract to get ranking (where 1 is the top scoring, because sorting was in ascending order)
ranking = sorted.shape[0] - r
rankings[i, j] = int(ranking)
input_tokens = [t for t in self.tokens[0]]
output_tokens = [repr(self.tokenizer.decode(t)) for t in watch]
lm_plots.plot_inner_token_rankings_watch(input_tokens, output_tokens, rankings,
position + self.n_input_tokens if self.model_type == 'enc-dec' else position)
if 'printJson' in kwargs and kwargs['printJson']:
data = {'input_tokens': input_tokens,
'output_tokens': output_tokens,
'rankings': rankings}
print(data)
return data
run_nmf(self, **kwargs)
Run Non-negative Matrix Factorization on network activations of FFNN. Returns an NMF object which holds the factorization model and data and methods to visualize them.
Source code in ecco/output.py
def run_nmf(self, **kwargs):
"""
Run Non-negative Matrix Factorization on network activations of FFNN. Returns an [NMF]() object which holds
the factorization model and data and methods to visualize them.
"""
return NMF(self.activations,
n_input_tokens=self.n_input_tokens,
token_ids=self.token_ids,
_path=self._path,
tokens=self.tokens,
collect_activations_layer_nums=self.collect_activations_layer_nums,
**kwargs)
saliency(self, attr_method='grad_x_input', style='minimal', **kwargs)
Explorable showing saliency of each token generation step.
Hovering-over or tapping an output token imposes a saliency map on other tokens
showing their importance as features to that prediction.
Examples:
```python
import ecco
lm = ecco.from_pretrained('distilgpt2')
text= "The countries of the European Union are:
- Austria
- Belgium
- Bulgaria
4."
output = lm.generate(text, generate=20, do_sample=True)
# Show saliency explorable output.saliency() ``` Which creates the following interactive explorable:  If we want more details on the saliency values, we can use the detailed view: ```python # Show detailed explorable output.saliency(style="detailed") ``` Which creates the following interactive explorable:  Details: This view shows the Gradient * Inputs method of input saliency. The attribution values are calculated across the embedding dimensions, then we use the L2 norm to calculate a score for each token (from the values of its embeddings dimension) To get a percentage value, we normalize the scores by dividing by the sum of the attribution scores for all the tokens in the sequence.
Source code in ecco/output.py
def saliency(self, attr_method: Optional[str] = 'grad_x_input', style="minimal", **kwargs):
"""
Explorable showing saliency of each token generation step.
Hovering-over or tapping an output token imposes a saliency map on other tokens
showing their importance as features to that prediction.
Examples:
```python
import ecco
lm = ecco.from_pretrained('distilgpt2')
text= "The countries of the European Union are:\n1. Austria\n2. Belgium\n3. Bulgaria\n4."
output = lm.generate(text, generate=20, do_sample=True)
# Show saliency explorable
output.saliency()
```
Which creates the following interactive explorable:

If we want more details on the saliency values, we can use the detailed view:
```python
# Show detailed explorable
output.saliency(style="detailed")
```
Which creates the following interactive explorable:

Details:
This view shows the Gradient * Inputs method of input saliency. The attribution values are calculated across the
embedding dimensions, then we use the L2 norm to calculate a score for each token (from the values of its embeddings dimension)
To get a percentage value, we normalize the scores by dividing by the sum of the attribution scores for all
the tokens in the sequence.
"""
position = self.n_input_tokens
importance_id = position - self.n_input_tokens
tokens = []
attribution = self.attribution[attr_method]
for idx, token in enumerate(self.tokens[0]):
type = "input" if idx < self.n_input_tokens else 'output'
if idx < len(attribution[importance_id]):
imp = attribution[importance_id][idx]
else:
imp = 0
tokens.append({'token': token,
'token_id': int(self.token_ids[0][idx]),
'type': type,
'value': str(imp), # because json complains of floats
'position': idx
})
data = {
'tokens': tokens,
'attributions': [att.tolist() for att in attribution]
}
d.display(d.HTML(filename=os.path.join(self._path, "html", "setup.html")))
d.display(d.HTML(filename=os.path.join(self._path, "html", "basic.html")))
# viz_id = 'viz_{}'.format(round(random.random() * 1000000))
if (style == "minimal"):
js = f"""
requirejs(['basic', 'ecco'], function(basic, ecco){{
const viz_id = basic.init()
// ecco.interactiveTokens(viz_id, {{}})
window.ecco[viz_id] = new ecco.MinimalHighlighter({{
parentDiv: viz_id,
data: {data},
preset: 'viridis'
}})
window.ecco[viz_id].init();
window.ecco[viz_id].selectFirstToken();
}}, function (err) {{
console.log(err);
}})"""
elif (style == "detailed"):
js = f"""
requirejs(['basic', 'ecco'], function(basic, ecco){{
const viz_id = basic.init()
window.ecco[viz_id] = ecco.interactiveTokens(viz_id, {data})
}}, function (err) {{
console.log(err);
}})"""
d.display(d.Javascript(js))
if 'printJson' in kwargs and kwargs['printJson']:
print(data)
return data